
Optimizing Network Operations Centers With Automation
For enterprise networks, NOC teams can face more than 10,000 network incidents per month in varying scale. Handling this volume, even with a large team, is nearly impossible. To optimize the effectiveness of a NOC, automation can help organizations achieve end-to-end visibility, faster diagnoses, and streamlined collaboration.
Gain Visibility Into Traffic Paths
Monitoring and troubleshooting an enterprise network requires visibility into the infrastructure and design of the network. When there’s a problem, engineers receiving a ticket often spend a lot of time tracing the path of the problem area. Even organizations who are diligent about documenting their network struggle with this because it is not possible to document all path combinations.
Since a network diagram doesn’t exist for each traffic flow, engineers rely on traceroute and the command-line interface (CLI) to understand traffic paths. Traceroute is very limiting as it’s a manual process—outputs are only in static text, asymmetric paths cannot be seen easily, and it does not report on layer-2 hops. Engineers need better visibility, and with NetBrain, only the source and destination details are needed to map any traffic flow instantly. Since NetBrain maps are dynamic, engineers can analyze network design, performance and changes made on that path in seconds. With traceroute or the CLI, this can take hours.
Automate Network Diagnoses
While visibility is important, automating the diagnosis process is equally critical when there are thousands of incidents every week—and thousands of potential root causes for each. When engineers identify the problem area, they often spend hours running multiple diagnoses on every single device using the CLI. NetBrain saves time by automating CLI commands and data analytics on all target devices, while selecting meaningful insights from CLI output and showing it on a Dynamic Map. This can save hours during troubleshooting as no time is wasted manually reading hundreds of lines of CLI output.
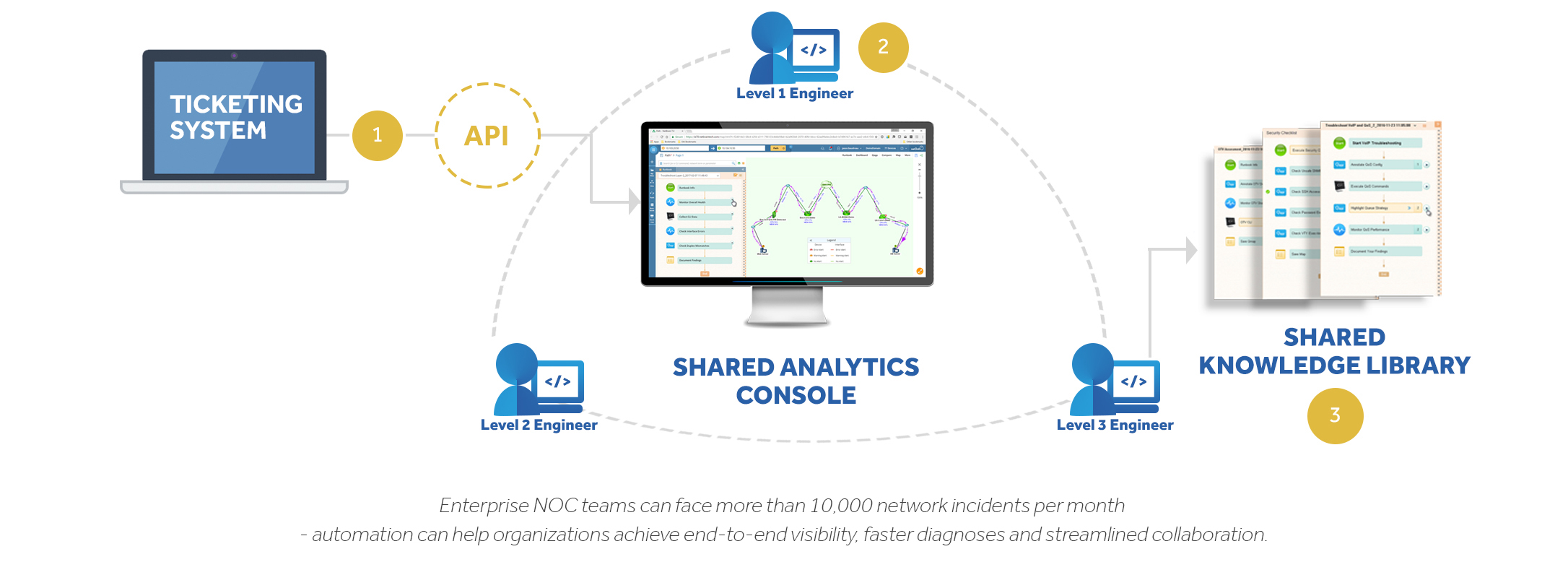
NOCs also have no shortage of tools, ranging from ticketing systems and monitoring tools to security and event management systems, all while operating manually through the CLI. Simplifying that process with automation is critical in reducing Mean Time to Repair (MTTR). With NetBrain, a Dynamic Map serves as a single pane of glass by integrating data from all these systems for pinpoint visualization and faster diagnosis. In addition, through NetBrain’s RESTful APIs, third-parties can automatically trigger NetBrain into action by mapping problem areas and executing pre-defined diagnostic steps. This is especially helpful while tracking down intermittent issues that cannot be reproduced easily.
Streamline Collaboration and Best Practices
In our recent survey, 45% of network engineers and managers cited lack of collaboration as the number one challenge for effective troubleshooting. Inefficient collaboration across the different levels of the NOC and other network teams can create issues that lead to delayed responses. For instance, during issue escalation, organizations often have multiple engineers repeating the same troubleshooting step which is highly inefficient.
Using a simple URL, NetBrain allows all engineers working on an issue to have access to the same information in real-time. With Dynamic Maps and Executable Runbooks, all past efforts are visible in an easy-to-understand format, preventing duplicate work. Engineers save time by instantly sharing data in a highly consumable format (a map), instead of incomplete notes and CLI outputs. This information can also be repurposed towards solving more systemic issues or evolving the network.
It is not unusual for NOC teams to face a recurrence of a previous issue. By automating best practices for previously solved problems, NOCs can significantly reduce MTTR. While a NOC can help enterprises feel like they have their network under control, organizations should ensure that the NOC team is optimized to ensure strong network availability and service delivery.